
Darrere la fàcil connectivitat de la qual gaudeix gran part del món, les xarxes de telecomunicacions del mercat treballen establint connexions de forma complexa i difícl, autenticant usuaris i verificant serveis.
 |
| Font: Pinterest.com |
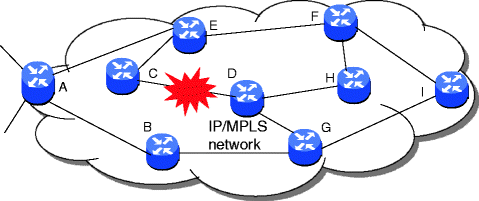
Quan es produeix un error, pot ser difícil que els proveïdors trobin la causa principal perquè es pot generar un missatge d'error en un lloc diferent d'una xarxa que el lloc on es va produir l'error real.
Per obtenir informació sobre l'origen d'aquests errors, els investigadors han analitzat els registres d'errors relacionats amb milions de missatges intercanviats a través de la xarxa d'AT&T. L'objectiu del grup era conèixer sobretot els esdeveniments latents. Els errors de latència poden provocar retards en la propagació i transmissió de trucades, problemes de desconnexió i fer colls d’ampolla de la xarxa. Cada error pot produir una seqüència de missatges, del tipus i la freqüència dels quals pot variar en funció de la latència entre els diversos elements de xarxa, càrrega de xarxa i altres esdeveniments.
 |
| Font: Springer Link |
S'han provat un conjunt d'algorismes que poden agrupar les dades brutes d'errors en incidències importants descrites per paraules clau importants, no s'està identificant la causa de les incidències, simplement s'estan separant els missatges en grups, on cada grup consisteix en missatges generats per una sola incidència. A més, s'identifiquen els missatges clau associats a cada incidència de manera que un operador de xarxa pot utilitzar aquestes agrupacions per identificar la causa arrel.
En una xarxa real, els errors que provenen de diferents ubicacions geogràfiques podrien estar relacionats entre si, i de vegades un error físic porta milers de missatges d’error. Per exemple per fer una trtucada entre dos punts, han de verificar les credencials, que es troben en l'estació d'origen.
Un cop fet això, la trucada s'encamina a través de la xarxa des del punt d¡origen al punt destí de manera que, si un encaminador es descompon en algun lloc d'aquesta xarxa, es produirien informes d'error de totes les xarxes i ubicacions connectades entre els dos punts. Aquest grup de missatges d’error en el registre d’errors, és el que s'anomena una incidpencia.
 |
Font: iStockphoto
|
És aquí on entra el nou algorisme. de manera que en funció de la mida dels registres d’errors, un enginyer pot analitzar els missatges i esbrinar quins van ser causats per la mateixa incidència.
Aquest algorisme agrupa aquests missatges en poques icidències importants. També, proporciona missatges que sovint es produeixen en aquestes incidències aparegudes. Aquesta agrupació de missatges fa que el registre de missatges sigui interpretable per enginyers i així, pot ajudar a desxifrar la causa principal de l’error.
Durant la recerca, l'equip d'ivestigadors van considerar que van contenir 97 milions de missatges, de 39.330 tipus, enviats durant 15 dies. Aquests incloïen textos syslog (missatges brut de text generats pel programari associat a elements específics de xarxa, com ara un servidor, un repetidor o una estació base a un servidor de registre i que inclouen una marca de temps i el text del missatge que descriu l'error) i les alarmes (que indiqueu condicions específiques d’error en un element de xarxa). Els investigadors van aplicar , a aquestes dades , un algorisme de dues etapes, anomenat Change-point Detection - Latent Dirichlet Allocation (CD-LDA), que utilitza l’algorisme LDA existent com a subrutina.
Com a resultat, durant les sis hores que va trigar a executar-se el LDA, aquest conjunt de dades es poden reduir mitjançant l’ús de versions més ràpides de l’algoritme LDA. Això fa que l’estudi sigui “molt escalable”, per detectar errors en una xarxa comercial.
Font: AT&T
Cap comentari:
Publica un comentari a l'entrada